设计文档综述
前言
P6 仅仅是在 P5 基础上加上一些指令而已。
数据通路设计
数据通路和实验指导书相仿。
顶层模块主要包含 $5$ 级流水线模块和额外的一个转发控制器。
如下图所示: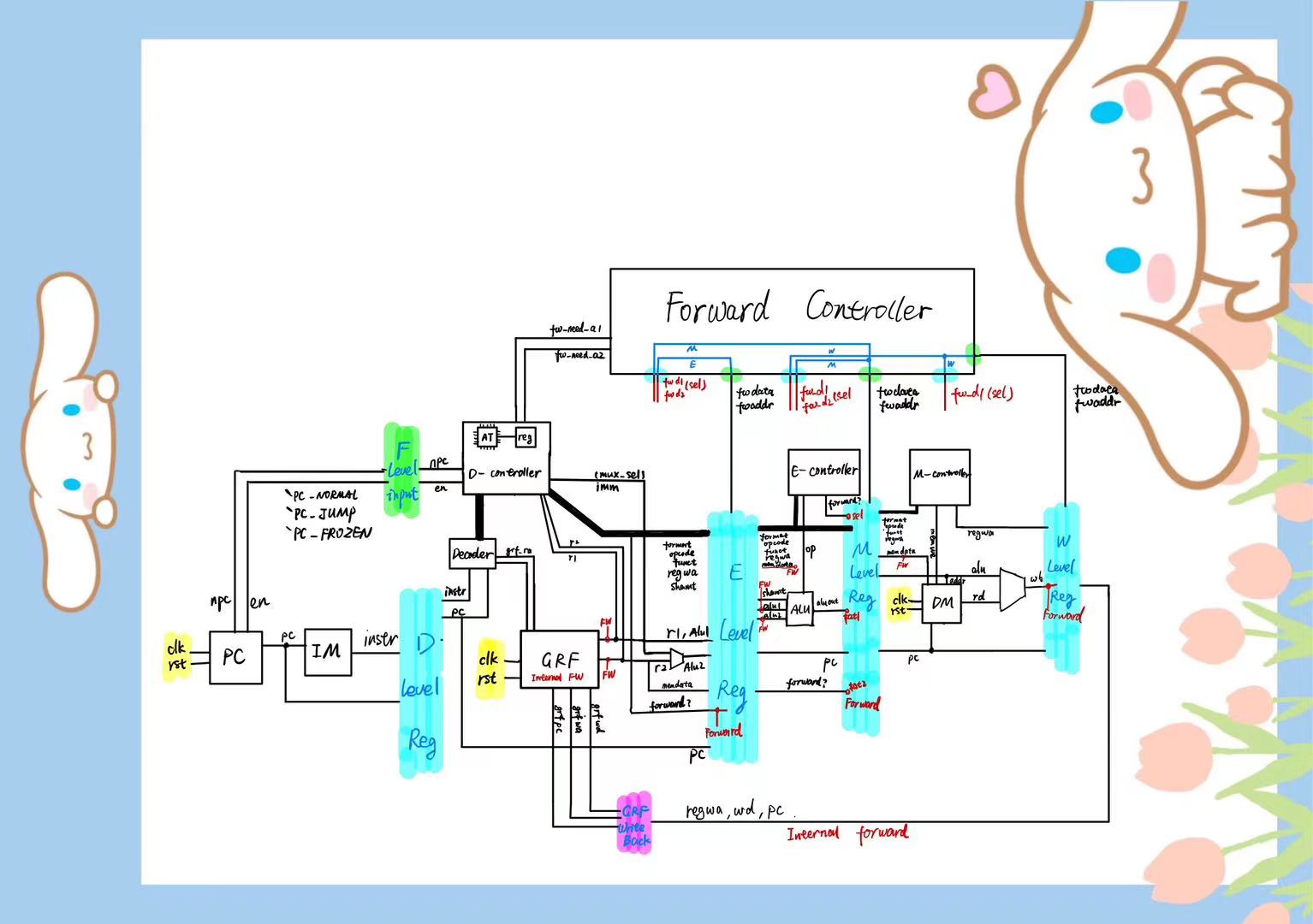
模块文件结构
大致结构是3层,第一层是顶层模块,用于桥接各级流水线;第二层是各级流水线,以及独立于流水线的转发控制模块;第三层是各个零碎的部件。各级流水线寄存器都位于同名流水线内部。如 D 级流水线寄存器在 Decode 模块内。
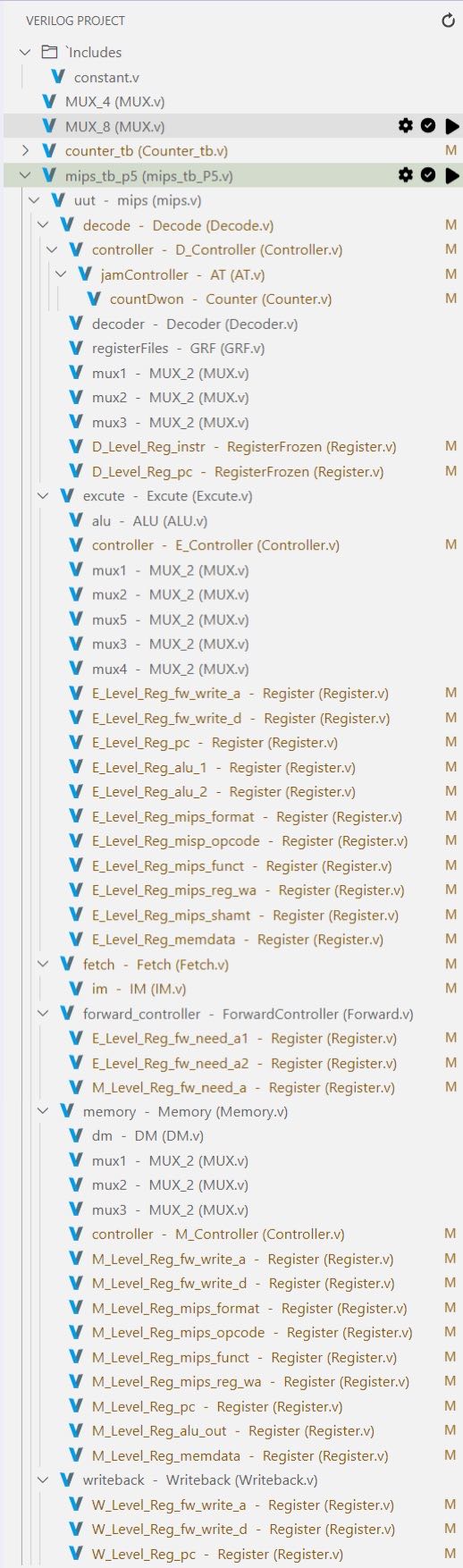
第二层模块概述
Fetch
模块声明:
module Fetch(
input clk,
input reset,
input [31:0] F_npc,
input [1 :0] F_pcen,
output [31:0] D_instr,
output [31:0] D_pc
);端口定义如下:
包含的子模块:
- IM
Decode
模块声明:
module Decode(
// global
input clk,
input reset,
// exchange with Fetch
output [31: 0] F_npc,
output [1 : 0] F_pcen,
// get register in
input [31: 0] D_instr_in,
input [31: 0] D_pc_in,
// exchange with Writeback
input [31: 0] writeback_grf_wd,
input [4 : 0] writeback_grf_wa,
input [31: 0] writeback_grf_pc,
// exchange with forward controller
output [4 : 0] fw_need_a1,
output [4 : 0] fw_need_a2,
input [31: 0] fw_need_d1,
input [31: 0] fw_need_d2,
input fw_need_sel1,
input fw_need_sel2,
// to next level's register
output [4 : 0] E_fw_write_a,
output [31: 0] E_fw_write_d,
output [31: 0] E_pc,
output [31: 0] E_alu_1,
output [31: 0] E_alu_2,
output [2 : 0] E_mips_format,
output [5 : 0] E_mips_opcode,
output [5 : 0] E_mips_funct,
output [4 : 0] E_mips_reg_wa,
output [4 : 0] E_mips_shamt,
output [31: 0] E_memdata
);端口定义如下:
包含的子模块:
- D_Controller
- Decoder
- GRF
- MUX_2 (3)
- RegisterFrozen (2)
Execute
模块声明:
module Execute(
// global
input clk,
input reset,
// get register in
input [4 : 0] E_fw_write_a_in,
input [31: 0] E_fw_write_d_in,
input [31: 0] E_pc_in,
input [31: 0] E_alu_1_in,
input [31: 0] E_alu_2_in,
input [2 : 0] E_mips_format_in,
input [5 : 0] E_mips_opcode_in,
input [5 : 0] E_mips_funct_in,
input [4 : 0] E_mips_reg_wa_in,
input [4 : 0] E_mips_shamt_in,
input [31: 0] E_memdata_in,
// exchange with forward controller
input [31: 0] fw_need_d1,
input [31: 0] fw_need_d2,
input fw_need_sel1,
input fw_need_sel2,
// notice forward controller
output [4 : 0] E_fw_write_a_out,
output [31: 0] E_fw_write_d_out,
// to next level's register
output [4 : 0] M_fw_write_a,
output [31: 0] M_fw_write_d,
output [2 : 0] M_mips_format,
output [5 : 0] M_mips_opcode,
output [5 : 0] M_mips_funct,
output [4 : 0] M_mips_reg_wa,
output [31: 0] M_pc,
output [31: 0] M_alu_out,
output [31: 0] M_memdata
);端口定义如下:
包含的子模块:
- ALU
- E_Controller
- MUX_2 (5)
- Register (11)
Memory
模块声明:
module Memory(
// global
input clk,
input reset,
// get register in
input [4 : 0] M_fw_write_a_in,
input [31: 0] M_fw_write_d_in,
input [2 : 0] M_mips_format_in,
input [5 : 0] M_mips_opcode_in,
input [5 : 0] M_mips_funct_in,
input [4 : 0] M_mips_reg_wa_in,
input [31: 0] M_pc_in,
input [31: 0] M_alu_out_in,
input [31: 0] M_memdata_in,
// exchange with forward controller
input [31: 0] fw_need_d,
input fw_need_sel,
// notice forward controller
output [4 : 0] M_fw_write_a_out,
output [31: 0] M_fw_write_d_out,
// to next level's register
output [4 : 0] W_fw_write_a,
output [31: 0] W_fw_write_d,
output [31: 0] W_pc
);端口定义如下:
包含的子模块:
- DM
- MUX_2 (3)
- M_Controller
- Register (9)
Writeback
模块声明:
module Writeback(
// global
input clk,
input reset,
// get register in
input [4 : 0] W_fw_write_a_in,
input [31: 0] W_fw_write_d_in,
input [31: 0] W_pc_in,
// notice forward controller
output [4 : 0] W_fw_write_a_out,
output [31: 0] W_fw_write_d_out,
// exchange with Register Files
output [4 : 0] writeback_grf_wa,
output [31: 0] writeback_grf_wd,
output [31: 0] writeback_grf_pc
);端口定义如下:
包含的子模块:
- Register (3)
ForWardController
模块声明:
module ForwardController(
input clk,
input reset,
input [4: 0] D_fw_need_a1,
input [4: 0] D_fw_need_a2,
input [4: 0] E_fw_write_a,
input [31:0] E_fw_write_d,
input [4: 0] M_fw_write_a,
input [31:0] M_fw_write_d,
input [4: 0] W_fw_write_a,
input [31:0] W_fw_write_d,
output reg D_fw_need_sel1,
output reg [31:0] D_fw_need_d1,
output reg D_fw_need_sel2,
output reg [31:0] D_fw_need_d2,
output reg E_fw_need_sel1,
output reg [31:0] E_fw_need_d1,
output reg E_fw_need_sel2,
output reg [31:0] E_fw_need_d2,
output reg M_fw_need_sel,
output reg [31:0] M_fw_need_d
);端口定义如下:
包含的子模块:
- Register (3)
MDU (Multiply-Divide Unit)
乘除法模块,乘除法模块我除了使用 verilog 已有的乘除法进行模拟外,也实现了不用自带乘除法的计算方式。实打实的要计算 5 或 10 个周期才能得到结果。
其中 MU 实现方式是每个周期计算 16bit * 16bit 然后累加起来;DU 实现方式是每个周期试商 4bit。
为了避免重复写代码,generate 真的非常重要。
思考题
为什么需要有单独的乘除法部件而不是整合进 ALU?为何需要有独立的 HI、LO 寄存器?
因为乘除法运算效率远低于 ALU,整合进 ALU 只会拖慢效率。独立的 HI、LO 寄存器也是为效率考虑的。一方面确实是乘除法需要两个寄存器保存结果,和其他指令不一致,另一方面,使用独立寄存器可以使得乘除法运算进行多个时钟周期而尽可能的不阻塞其他指令。
真实的流水线 CPU 是如何使用实现乘除法的?请查阅相关资料进行简单说明。
在真实的流水线 CPU 中,乘法通常有若干个较小的乘法单元组成(组合逻辑),然后每个周期计算特定的几位,依次累加起来,于是会在几个周期后得到正确的最终结果;除法通常使用试商法,通常也是使用组合逻辑在一个周期内计算 4 位左右的商,经过 8 个周期正好可以计算结束。
请结合自己的实现分析,你是如何处理 Busy 信号带来的周期阻塞的?
当且仅当 Busy 信号为高电平且当前指令为 mfhi 或 mflo 时对D级进行阻塞。
请问采用字节使能信号的方式处理写指令有什么好处?(提示:从清晰性、统一性等角度考虑)
使用字节使能大幅度提高 M 级的效率。这使得每个模块专注于自己的事情:控制器专注于提供控制信号,存储器决定最终存储地址。方便又快捷,何乐而不为。
请思考,我们在按字节读和按字节写时,实际从 DM 获得的数据和向 DM 写入的数据是否是一字节?在什么情况下我们按字节读和按字节写的效率会高于按字读和按字写呢?
我认为,只要需要支持按字节写就需要实现字节使能。如果只实现按字使能,就不得不先读取值再进行更改,这样数据通路就延长了,导致效率下降。
为了对抗复杂性你采取了哪些抽象和规范手段?这些手段在译码和处理数据冲突的时候有什么样的特点与帮助?
按照一定的规则对指令进行更详细的分类,这样每个控制器只需要先判断该指令分类需不需要自己处理,只有需要的情况下才对指令进行更细致的查看和分析。
在本实验中你遇到了哪些不同指令类型组合产生的冲突?你又是如何解决的?相应的测试样例是什么样的?
其实 P6 相较于 P5 仅仅增加了乘法器的冲突。在进行乘除指令后紧接着立即执行 mfhi 或 mflo 会造成严重冲突,理应进行长时间阻塞。而其他冲突和 P5 一致。构造样例如下:
lui $t0 0x0014 lui $t2 0xffff ori $t0 $t0 0x5678 ori $t1 $t1 0xabcd mult $t0 $t1 mfhi $s0 mflo $s1 mult $t0 $t2 mfhi $s0 mflo $s1 multu $t0 $t2 mfhi $s0 mflo $s1 s: beq $0 $0 s nop如果你是手动构造的样例,请说明构造策略,说明你的测试程序如何保证覆盖了所有需要测试的情况;如果你是完全随机生成的测试样例,请思考完全随机的测试程序有何不足之处;如果你在生成测试样例时采用了特殊的策略,比如构造连续数据冒险序列,请你描述一下你使用的策略如何结合了随机性达到强测的效果。
由于新增冲突就上述一条,所以构造上述测试样例依然足够。