设计方案综述
需要完成的指令如下:

这份 CPU 完全没有使用一个 Tunnel,属于是连线艺术了。
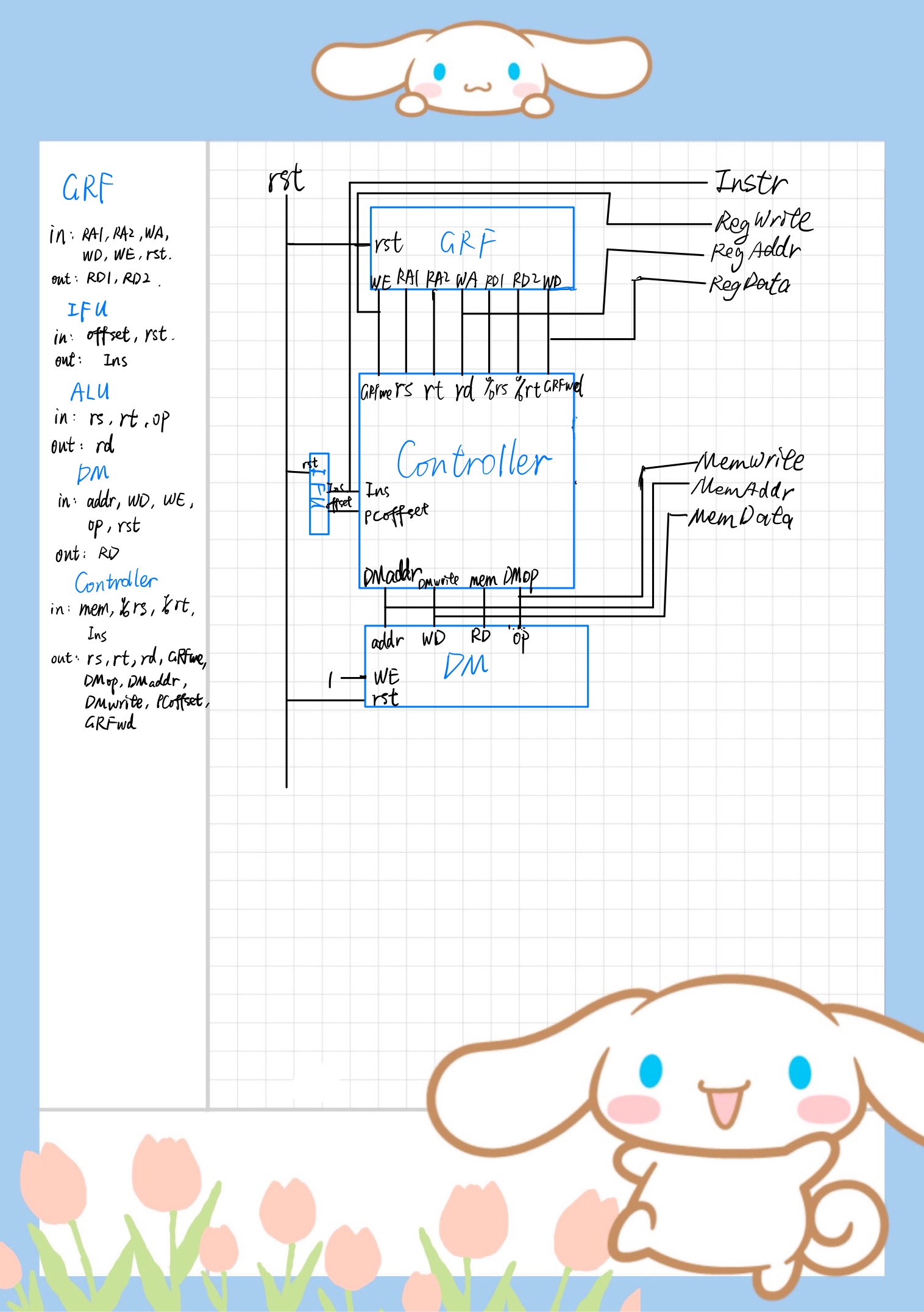
IFU
采用 $5 \times 32$ 的 ROM 实现,因此 PC 寄存器实际上是 PC >> 2 的值。所以 PC 每次固定 +1 即可,有 offset 时,就额外把 offset 加上即可。
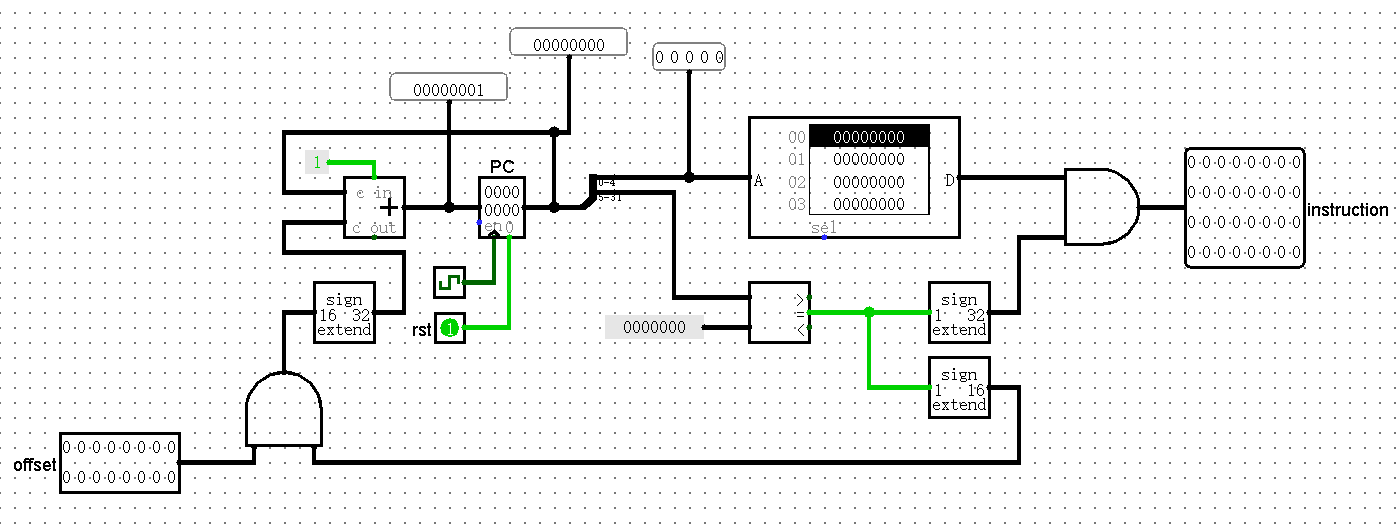
端口设置和外观:
| Label | Direction | Bit Width | Description |
|---|---|---|---|
| rst | in | 1 | async reset |
| offset | in | 16 | offset of branch operation |
| Instr | out | 32 | instruction |
GRF
Version 1
P0 课下的版本,简单粗暴。因为太丑被抛弃了。
Version 2
未完成版。WriteAddress 采用二维寻址。美观了不少。但是由于 ReadAddress 不是很好弄,就半途而废了。
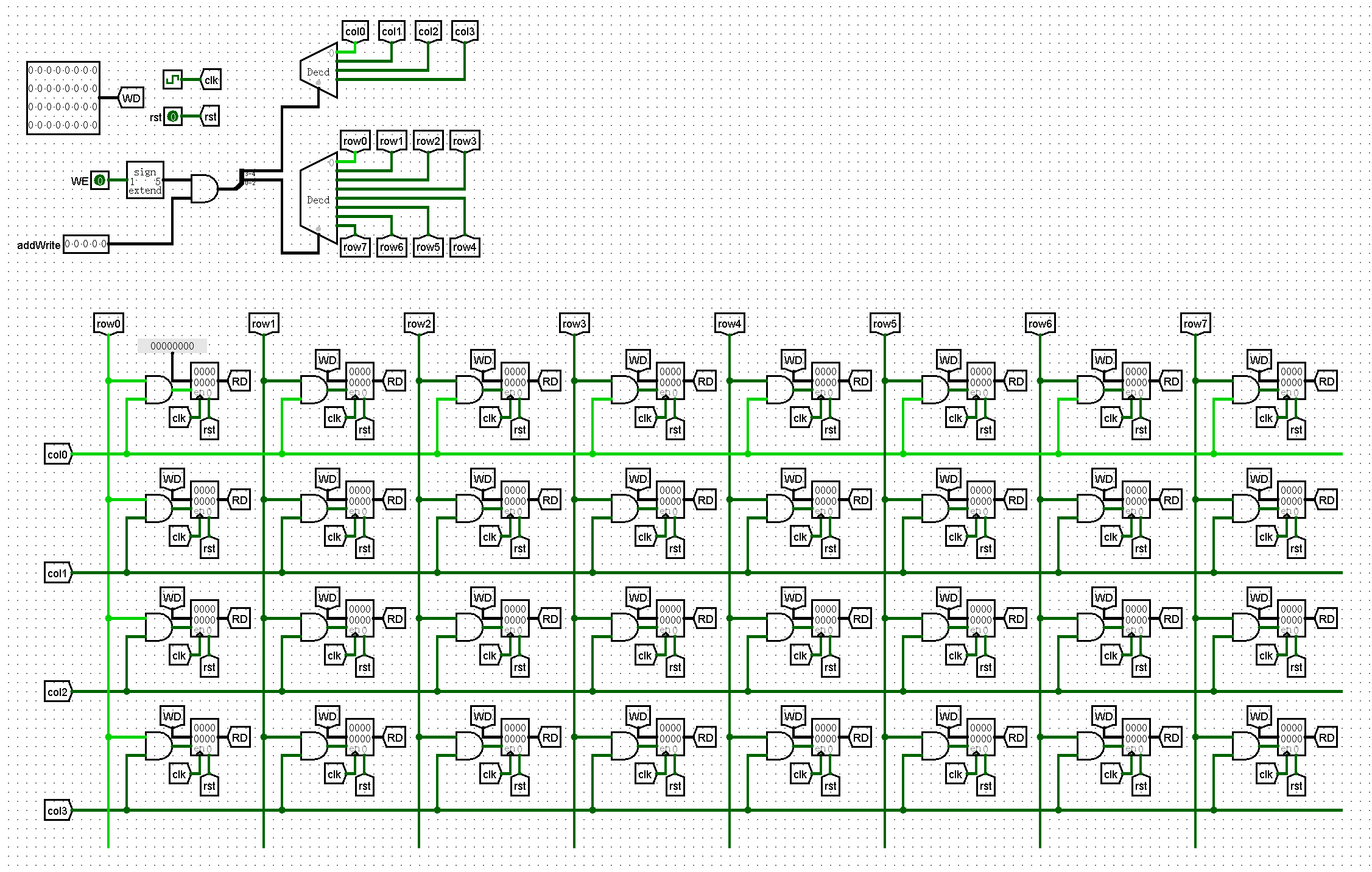
Version 3
终稿。受到二维寻址启发,改为多维二分寻址。具体行为是 GRF_R0 为 $2$ 个寄存器,地址长度为 1bit;GRF_R1 为 $2$ 个 GRF_R0 模块,地址长度为 2bit(高位选模块,低位传入模块);$\cdots$;GRF_Rx 为 $2$ 个 GRF_R(x-1) 模块,地址长度为 (x+1)bit(最高位选模块,剩下传入模块)。这样最大的好处就是,没有什么工作量,每层除了地址长度不同,其他都相同,因此可以直接复制粘贴完成。缺点是没法直观看到每个寄存器的值。
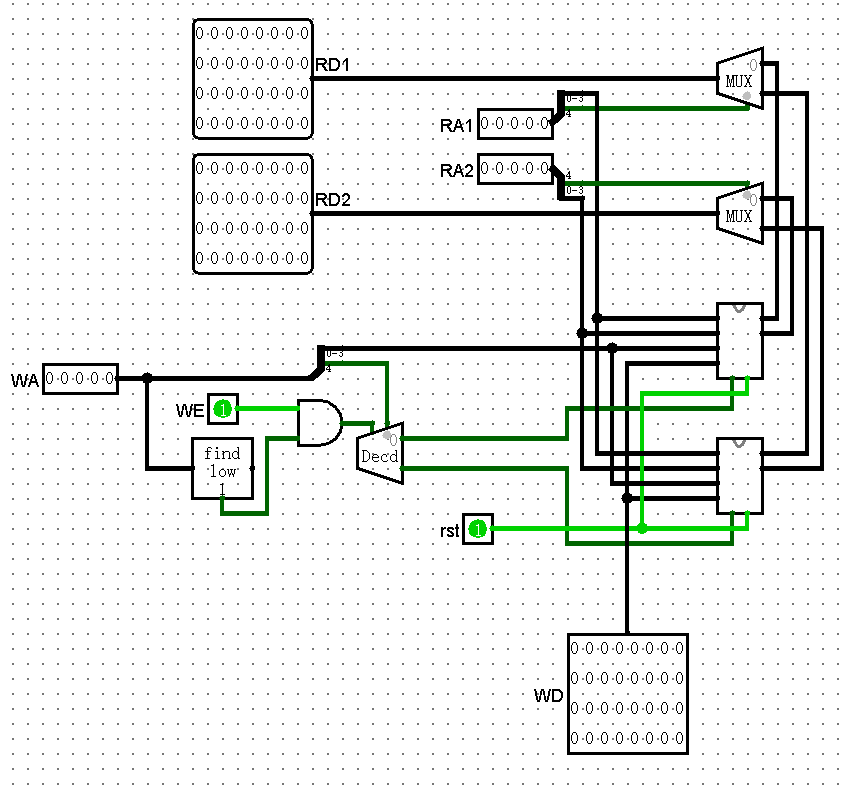
如你所见,最顶层的 GRF_R4 模块就是 GRF 模块了。需要注意的是,如果 WA 也就是 WriteAddress 为 00000 就需要特判不允许写入,因为不允许向 $zero 写入数据。
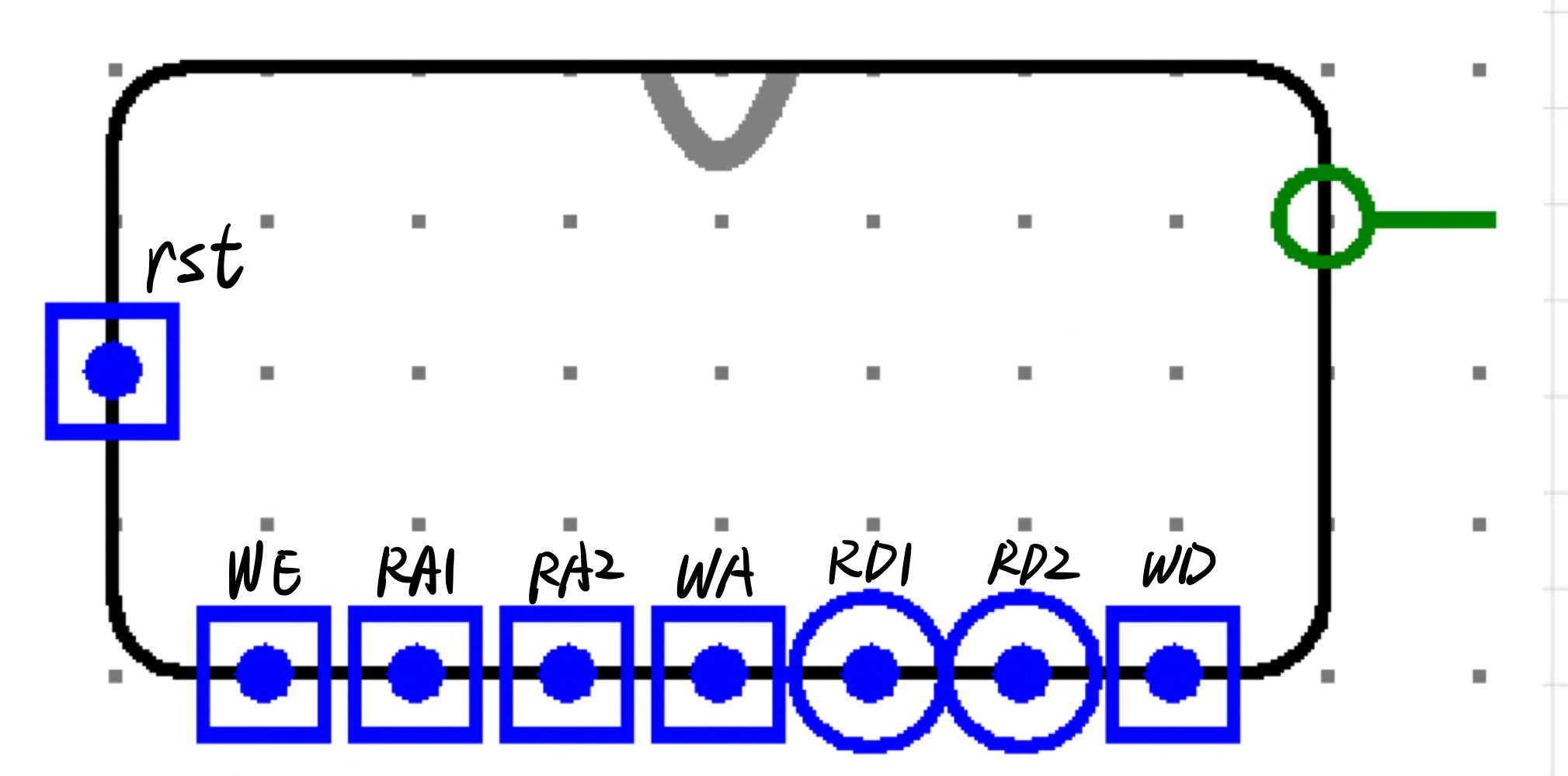
端口设置和外观:
| Label | Direction | Bit Width | Description |
|---|---|---|---|
| rst | in | 1 | async reset |
| WE | in | 1 | write enable |
| RA1 | in | 5 | read address 1 |
| RA2 | in | 5 | read address 2 |
| WA | in | 5 | write address |
| RD1 | out | 32 | read data 1 |
| RD2 | out | 32 | read data 2 |
| WD | in | 32 | write data |
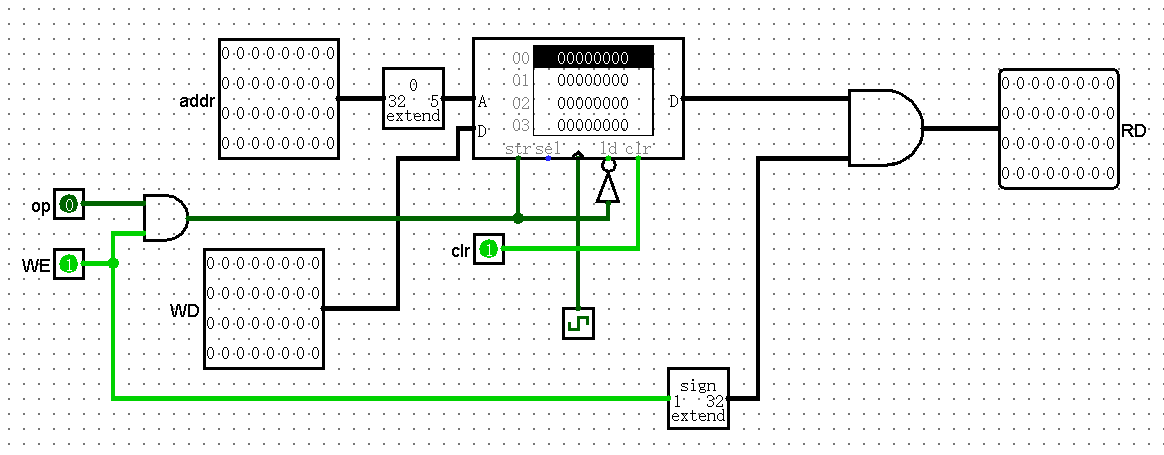
DM
大概就只是依照实验指导书搭建了一个。莫名奇妙为 DM 增加了一个使能端口。但是并没有任何实际作用,用 op 选择输入还是输出就足够了。所以最后 WE 端口直接连接的常数 1。addr 用的 32bit,或许可以方便以后拓展。
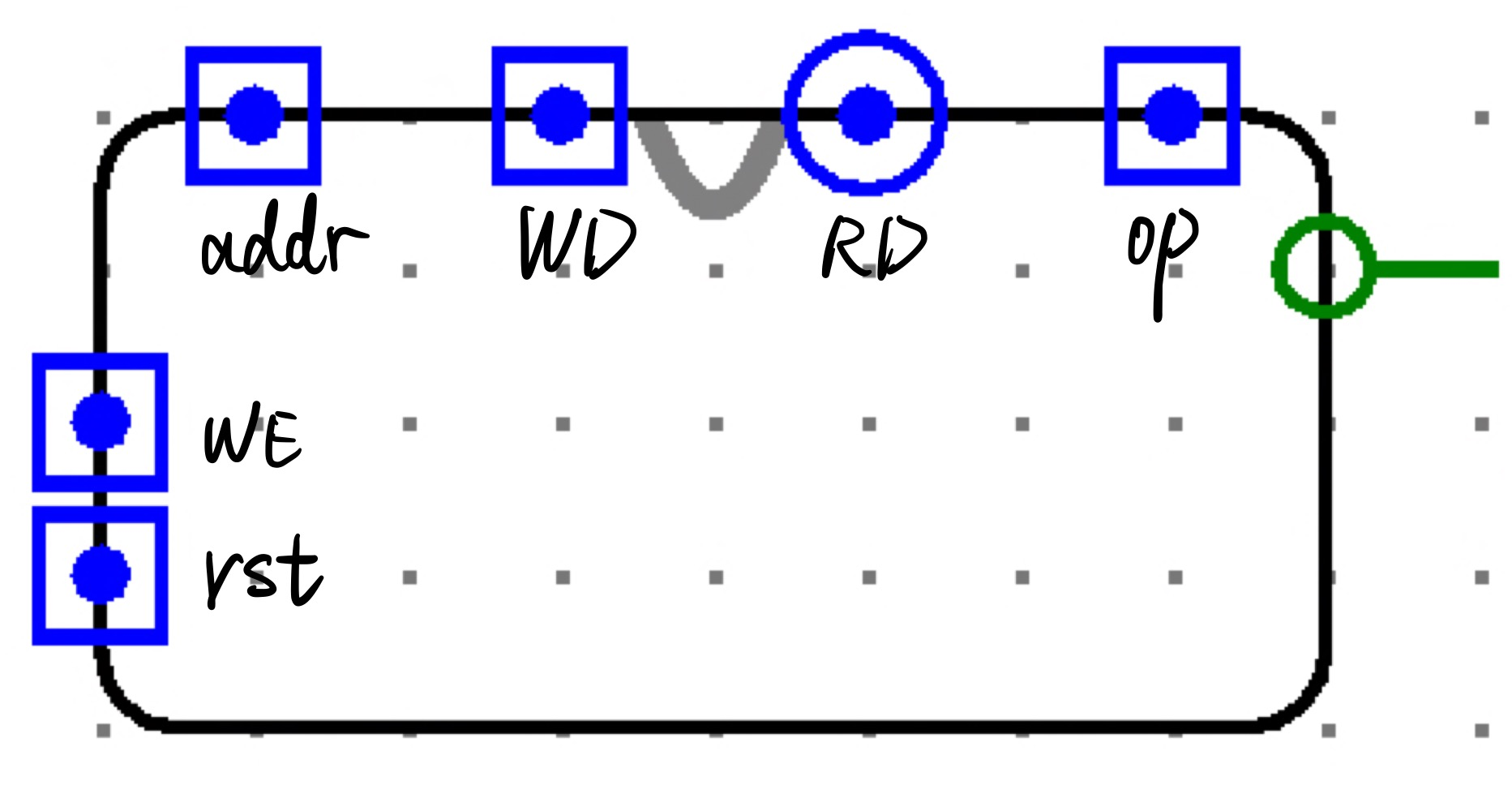
端口设置和外观:
| Label | Direction | Bit Width | Description |
|---|---|---|---|
| rst | in | 1 | async reset |
| WE | in | 1 | enable |
| addr | in | 32 | address |
| WD | in | 32 | write data |
| RD | out | 32 | read data |
| op | in | 1 | 0 if load, 1 if write |
ALU
简单的 ALU,集成了四册运算,简单位运算和逻辑移位。op 为 4bit, 方便扩展。但是对于 op = 1111,需要始终保证结果为 0x00000000。另外需要注意的是,由于考虑到要支持 sll 操作,移位操作中是 rt << rs 不是 rs << rt。当然这很不好,我本来有打算专门给 ALU 增加一个移位端口的,因为没时间了,摆烂了。
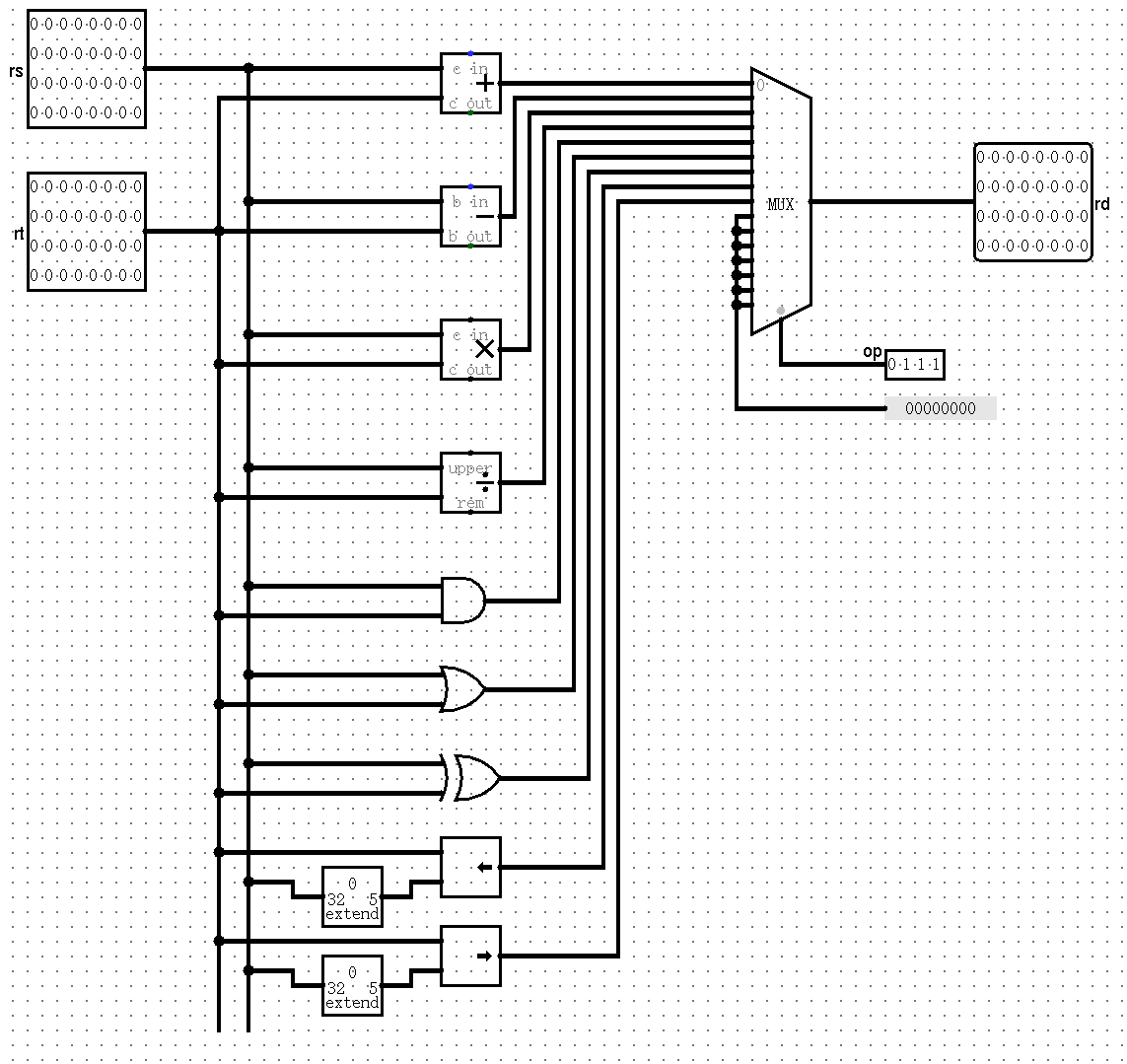
Controller
为了奇怪的执着而搭建的奇怪的 Controller。用了与或门阵列,但又没有完全用。为了执着的追求连线的快乐,依然没有使用任何 Tunnel,这或许会使得结构的可读性大幅度下降。
端口设置和外观:
| Label | Direction | Bit Width | Description |
|---|---|---|---|
| Instr | in | 32 | Instruction (from IFU) |
| PCoffset | out | 16 | PC offset (to IFU) |
| GRFwe | out | 1 | register write enable (to GRF) |
| rs | out | 5 | register $rs address (to GRF) |
| rt | out | 5 | register $rt address (to GRF) |
| rd | out | 5 | register $rd address (to GRF) |
| %rs | in | 32 | register $rs value (from GRF) |
| %rt | in | 32 | register $rt value (from GRF) |
| GRFwd | out | 32 | register write to $rd (to GRF) |
| DMaddr | out | 32 | memory access address (to DM) |
| DMwrite | out | 32 | data to write in memory (to DM) |
| mem | in | 32 | data load from memory (from DM) |
| DMop | out | 1 | 0 if load, 1 if write (to DM) |
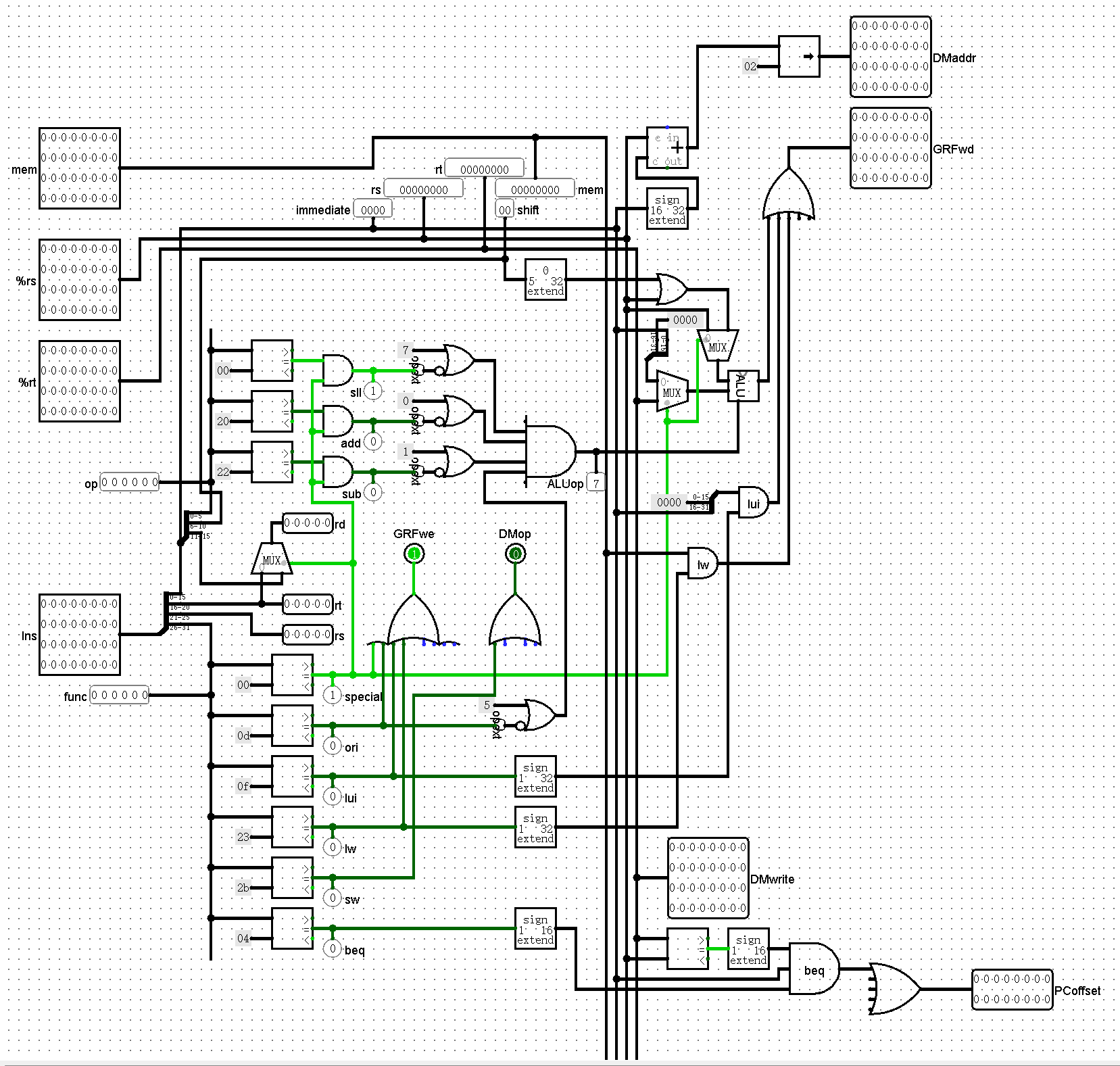
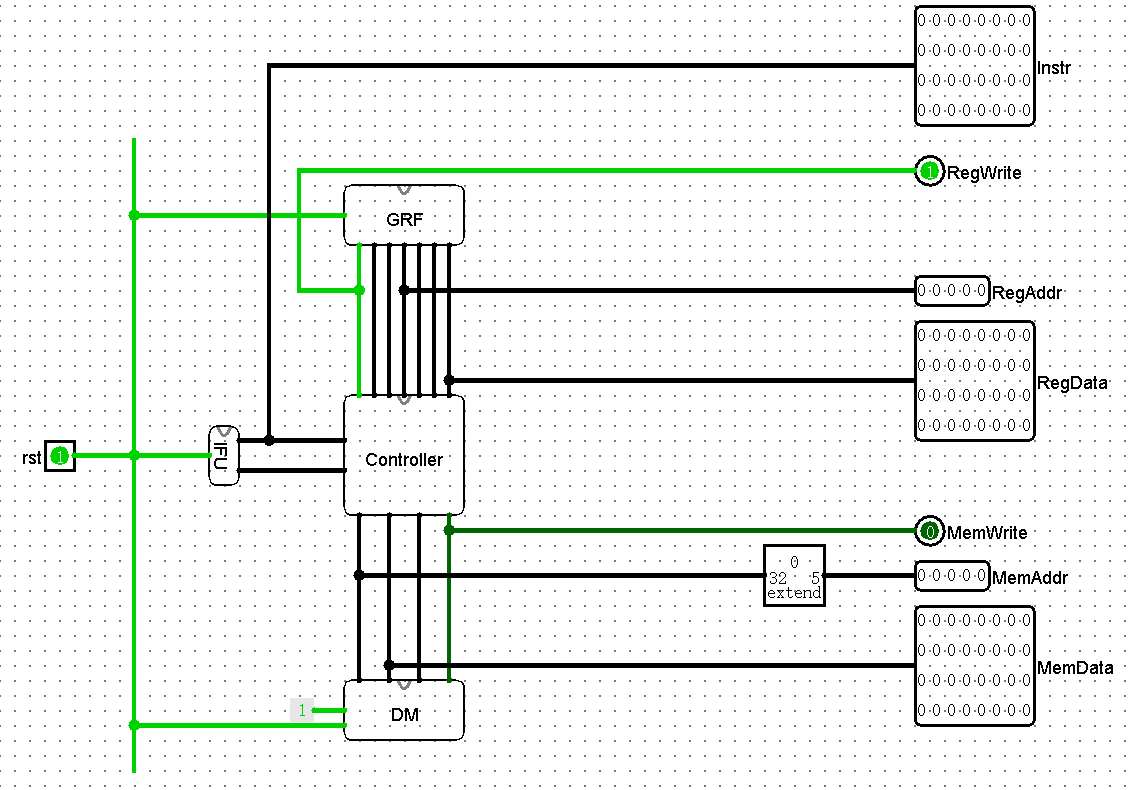
main
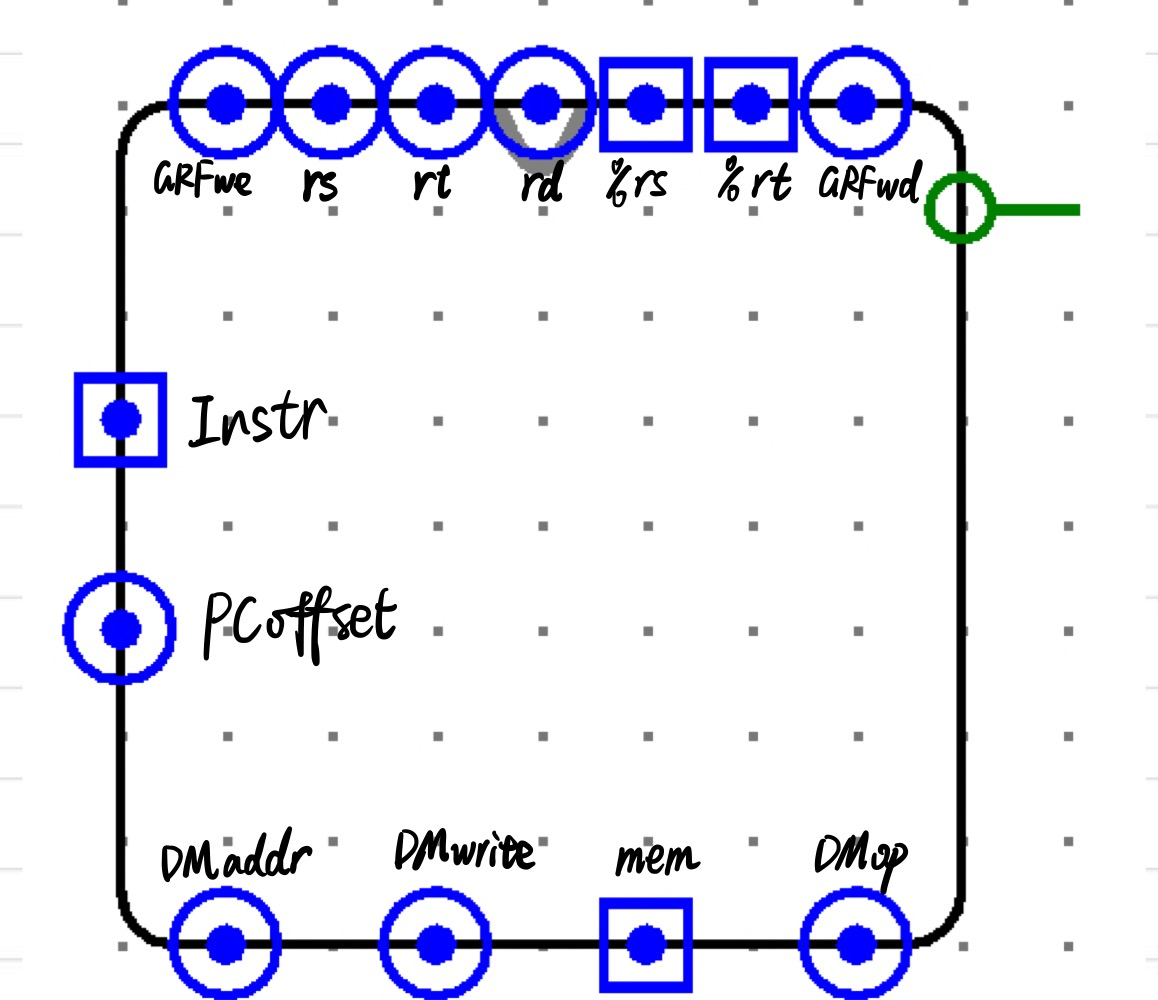
如你所见,其实上面外观是专门安排的,就是为了方便连线。草图如下:
最终连线结果如下:
测试方案
测试电路如下(同实验指导书):
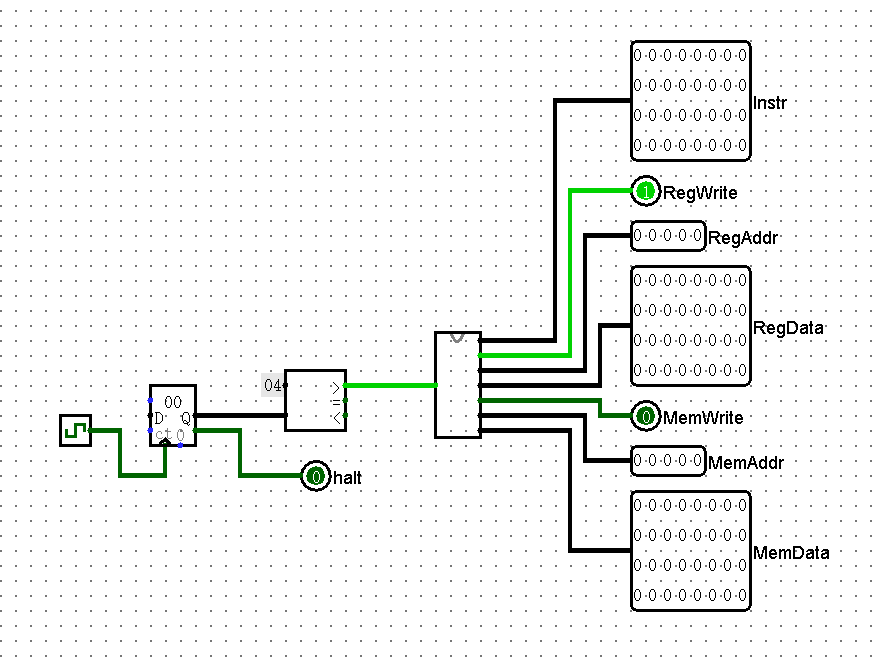
testcase1
实验书的测试数据。
v2.0 raw
341c0000
341d0000
34013456
00210820
8c010004
ac010004
3c027878
00411822
3c051234
34040005
00000000
ac85ffff
8c83ffff
10650001
1000000d
34670404
10e3000b
00000000
3c087777
3508ffff
00080022
34001100
00e65020
34080000
34090001
340a0001
010a4020
1109fffe
1000ffff结果如下:
In MIPS code 341c0000: register writing: $28 <= 0x00000000
In MIPS code 341d0000: register writing: $29 <= 0x00000000
In MIPS code 34013456: register writing: $1 <= 0x00003456
In MIPS code 00210820: register writing: $1 <= 0x000068ac
In MIPS code 8c010004: register writing: $1 <= 0x00000000
In MIPS code ac010004: memory writing: *00000001 <= 0x00000000
In MIPS code 3c027878: register writing: $2 <= 0x78780000
In MIPS code 00411822: register writing: $3 <= 0x78780000
In MIPS code 3c051234: register writing: $5 <= 0x12340000
In MIPS code 34040005: register writing: $4 <= 0x00000005
In MIPS code 00000000: register writing: $0 <= 0x00000000
In MIPS code ac85ffff: memory writing: *00000001 <= 0x12340000
In MIPS code 8c83ffff: register writing: $3 <= 0x12340000
In MIPS code 10650001:
In MIPS code 34670404: register writing: $7 <= 0x12340404
In MIPS code 10e3000b:
In MIPS code 00000000: register writing: $0 <= 0x00000000
In MIPS code 3c087777: register writing: $8 <= 0x77770000
In MIPS code 3508ffff: register writing: $8 <= 0x7777ffff
In MIPS code 00080022: register writing: $0 <= 0x88880001
In MIPS code 34001100: register writing: $0 <= 0x00001100
In MIPS code 00e65020: register writing: $10 <= 0x12340404
In MIPS code 34080000: register writing: $8 <= 0x00000000
In MIPS code 34090001: register writing: $9 <= 0x00000001
In MIPS code 340a0001: register writing: $10 <= 0x00000001
In MIPS code 010a4020: register writing: $8 <= 0x00000001
In MIPS code 1109fffe:
In MIPS code 010a4020: register writing: $8 <= 0x00000002
In MIPS code 1109fffe:
In MIPS code 1000ffff: testcase2
描述: 向 mem[x] 中写入 x*4 (x 从 $0$ 到 $29$),并全部把这些数相加,结果写入 mem[30]
mips代码如下:
# *** T2 *** #
ori $s0 $zero 0
ori $t0 $zero 0
ori $t1 $zero 120
ori $s6 $zero 4
loop: beq $t0 $t1 end
lw $t0 0($t0)
nop
lw $t2 0($t0)
add $s0 $s0 $t2
add $t0 $t0 $s6
beq $zero $zero loop
end: sw $s0 0($t1)
nop机器码如下 :
(PS:不知道是不是 LogiSim 的 bug,反正如果文件中的指令太少,手动载入 ROM 会有问题,所以在后面手动添加了 20*nop)
v2.0 raw
34100000
34080000
34090078
34160004
11090006
ad080000
00000000
8d0a0000
020a8020
01164020
1000fff9
ad300000
20*00000000结果如下(部分):
In MIPS code ad300000: memory writing: *0000001e <= 0x000006cctestcase3
描述:求斐波那契数列的前 $10$ 项,结果一次存入 mem[0-9]
mips代码如下:
ori $a0 $zero 10
ori $a1 $zero 0
# ***** FIB(N, arr[])***** #
ori $t1 $zero 1
ori $t2 $zero 0
ori $t0 $zero 0
ori $s1 $zero 1
loop: beq $t0 $a0 end
add $t3 $t1 $t2
add $t1 $zero $t2
add $t2 $zero $t3
sll $t3 $t0 2
add $t3 $t3 $a1
sw $t2 0($t3)
add $t0 $t0 $s1
beq $zero $zero loop
end: nop机器码如下:
v2.0 raw
3404000a
34050000
34090001
340a0000
34080000
34110001
11040008
012a5820
000a4820
000b5020
00085880
01655820
ad6a0000
01114020
1000fff7
15*00000000结果如下(部分):
In MIPS code ad6a0000: memory writing: *00000000 <= 0x00000001
In MIPS code ad6a0000: memory writing: *00000001 <= 0x00000001
In MIPS code ad6a0000: memory writing: *00000002 <= 0x00000002
In MIPS code ad6a0000: memory writing: *00000003 <= 0x00000003
In MIPS code ad6a0000: memory writing: *00000004 <= 0x00000005
In MIPS code ad6a0000: memory writing: *00000005 <= 0x00000008
In MIPS code ad6a0000: memory writing: *00000006 <= 0x0000000d
In MIPS code ad6a0000: memory writing: *00000007 <= 0x00000015
In MIPS code ad6a0000: memory writing: *00000008 <= 0x00000022
In MIPS code ad6a0000: memory writing: *00000009 <= 0x00000037备注
测试步骤见测试文档,本文档不再赘述。
思考题
1. 上面我们介绍了通过 FSM 理解单周期 CPU 的基本方法。请大家指出单周期 CPU 所用到的模块中,哪些发挥状态存储功能,哪些发挥状态转移功能。
DM,GRF,IM 均为转态储存功能。
Controller,ALU 为状态转移功能。
2. 现在我们的模块中 IM 使用 ROM, DM 使用 RAM, GRF 使用 Register,这种做法合理吗? 请给出分析,若有改进意见也请一并给出。
我认为是合理的。
因为 IM 一次导入无需变动,所以使用 ROM;
GRF 需要支持同时读取 2 个寄存器,写入一个,必须使用寄存器堆栈的方式;
DM 需要支持存取,但是不会同时进行,所以直接使用 RAM 即可。
3. 在上述提示的模块之外,你是否在实际实现时设计了其他的模块?如果是的话,请给出介绍和设计的思路。
我并没有设计其他模块。我认为使用推荐的模块已经足够。
4. 事实上,实现 nop 空指令,我们并不需要将它加入控制信号真值表,为什么?
因为
nop指令没有改变任何寄存器或内存,所以无论是否加入控制信号真值表都不会有任何影响。
实际上,注意到nop指令是sll指令的特殊情况,所以我直接实现了sll指令。
5. 上文提到,MARS 不能导出 PC 与 DM 起始地址均为 0 的机器码。实际上,可以避免手工修改的麻烦。请查阅相关资料进行了解,并阐释为了解决这个问题,你最终采用的方法。
我只是使用
java -jar Mars4_5.jar a dump .text HexText $fileNameWithoutExt.txt $fileName指令导出了PC对应的机器码,并没有专门导出DM。因为我没有实现自动化测试。
6. 阅读 Pre 的 “MIPS 指令集及汇编语言” 一节中给出的测试样例,评价其强度(可从各个指令的覆盖情况,单一指令各种行为的覆盖情况等方面分析),并指出具体的不足之处。
该测试样例只是简单的进行了指令的堆砌。并没有考虑多种情况。不过我个人认为虽然确实缺少极端数据,但是在大多数情况下是足够了。

